DenseNet — Dense卷积网络(图像分类)
【导读】本文对Dense卷积网络的发展进行了综述。这是2017年的CVPR最佳论文奖,并拥有2000多篇论文引用。它由康威尔大学、清华大学和facebook AI共同合作完成。
作者 | Sik-Ho Tsang (原文:Review: DenseNet — Dense Convolutional Network (Image Classification))
编译 | Xiaowen
该译文转载自:https://mp.weixin.qq.com/s/F2GRDen0v2zbnHlB-xHioA
目录
1. Dense Block

在 andard ConvNet 中,输入图像经过多次卷积,得到高层次特征。
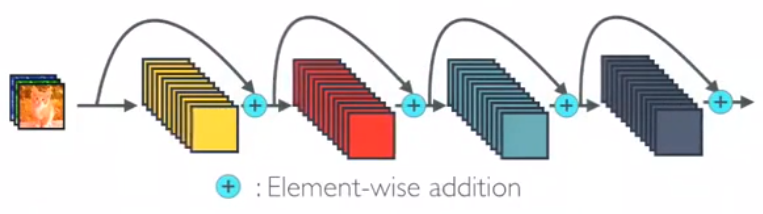
在 ResNet 中,提出了恒等映射( identity mapping )来促进梯度传播,同时使用使用 Element-wise addition 。它可以看作是将状态从一个 ResNet 模块传递到另一个 ResNet 模块的算法。 (It can be viewed as algorithms with a state passed from one ResNet module to another one.)
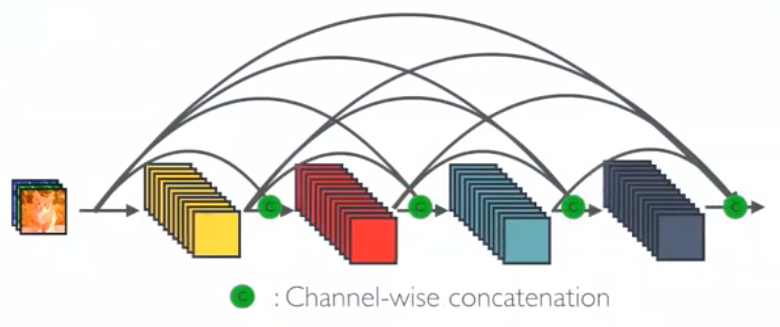
在 DenseNet 中,每个层从前面的所有层获得额外的输入,并将自己的特征映射传递到后续的所有层,使用级联(Concatenation)方式,每一层都在接受来自前几层的“集体知识(collective knowledge)”。(Concatenation is used. Each layer is receiving a “collective knowledge” from all preceding layers.)
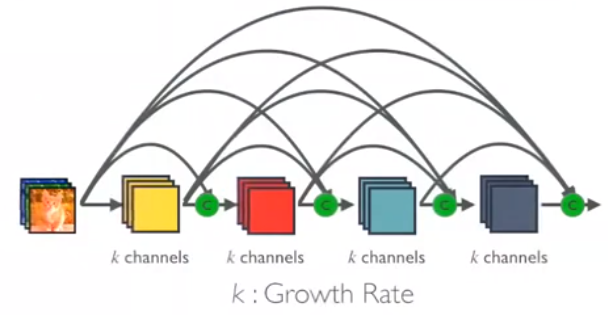
由于每个层从前面的所有层接收特征映射,所以网络可以更薄、更紧凑,即信道数可以更少。增长速率k是每个层的附加信道数。
因此,它具有较高的计算效率和存储效率。下图显示了前向传播中级联的概念:
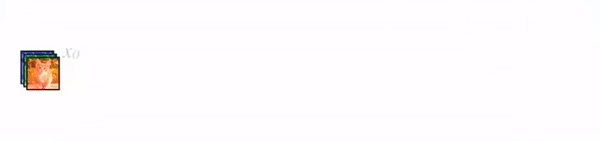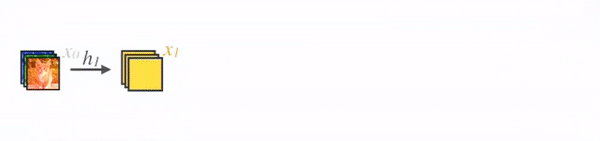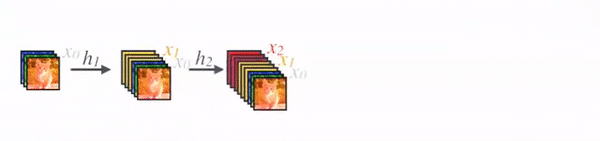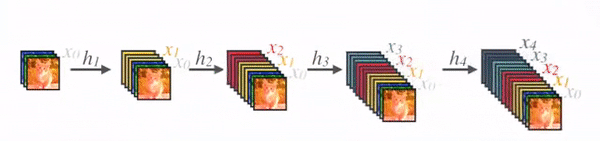
2. DenseNet 结构
2.1 基础 DenseNet 组成层
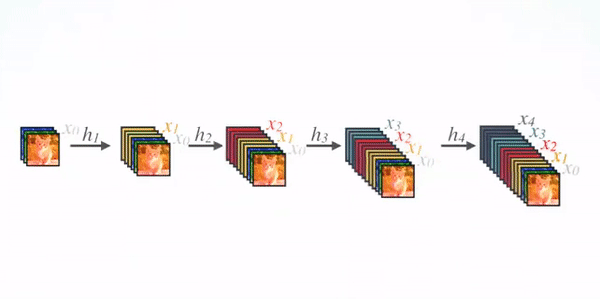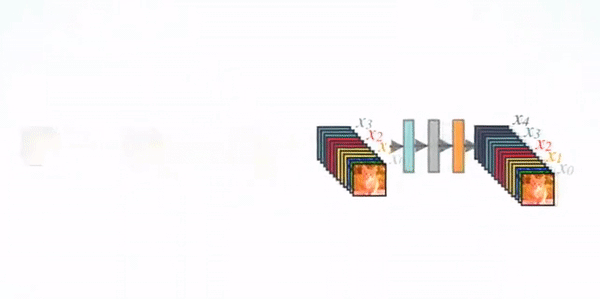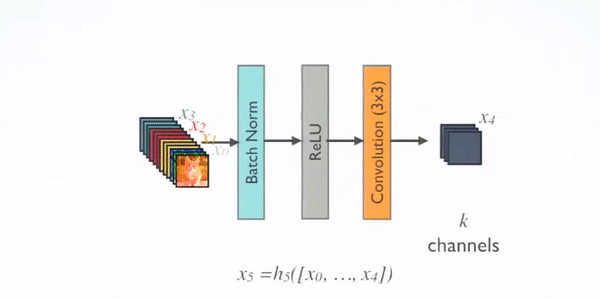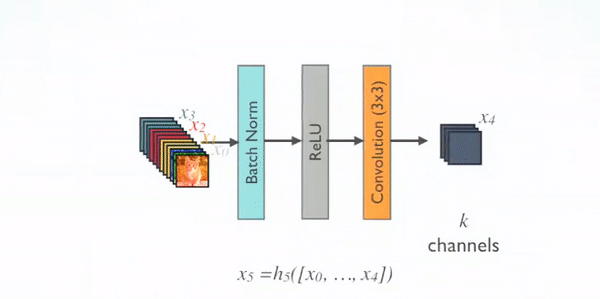
对于每个组成层使用 Pre-Activation Batch Norm (BN) 和 ReLU,然后用k通道的输出特征映射进行 $\boldsymbol{3 \times 3}$ 卷积,例如,将$x_0$、$x_1$、$x_2$、$x_3$ 转换为 $x_4$。这是 Pre-Activation ResNet 的想法。
2.2 DenseNet-B (Bottleneck 层)
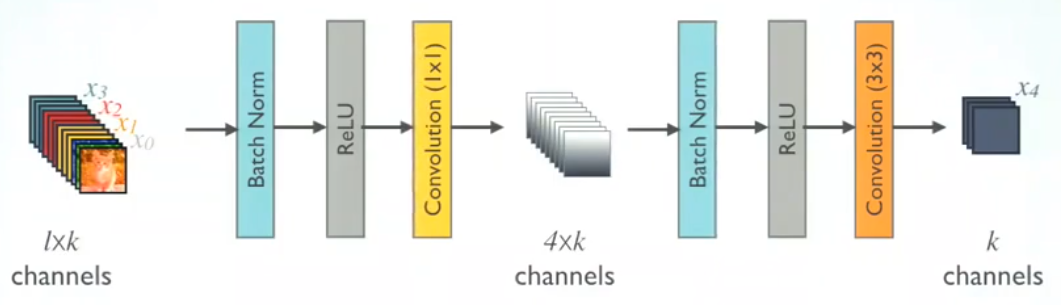
为了降低模型的复杂度和规模,在 BN-ReLU-3×3 conv 之前进行了 BN-ReLU-1×1 conv .
2.3 具有转换层(transition layer)的多Dense块
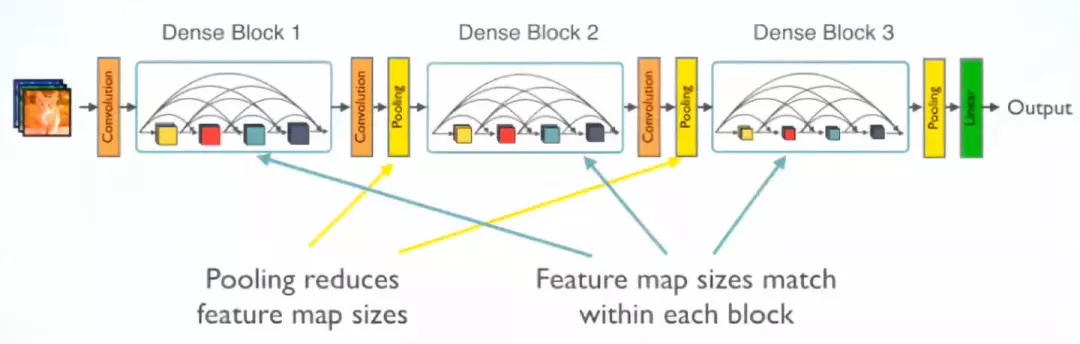
采用1×1 Conv和2×2平均池化作为相邻 dense block 之间的转换层。
特征映射大小在 dense block 中是相同的,因此它们可以很容易地连接在一起。
在最后一个 dense block 的末尾,执行一个全局平均池化,然后附加一个 Softmax 分类器。
2.4 DenseNet-BC (进一步压缩)
如果 Dense Block 包含 $m$ 个特征映射,则转换层(transition layer)生成 $\theta_m$ 输出特征映射,其中 $0 < \theta \leq 1$ 称为压缩因子。
当 $\theta = 1$ 时,跨转换层的特征映射数保持不变。$\boldsymbol{\theta < 1}$ 的 DenseNet 称为 DenseNet-C,在实验中采用 $\theta = 0.5$ 。
当同时使用 bottleneck 和 $\boldsymbol{\theta < 1}$ 时的转换层时,该模型称为 DenseNet-BC 模型。
最后,训练 with/without B/C 和不同 L 层 和 k growth rate 的 DenseNet。
3. DenseNet 的优势
3.1 Strong Gradient Flow
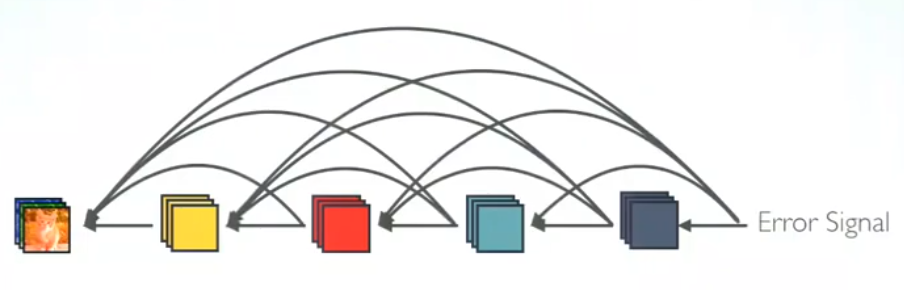
误差信号可以更直接地传播到早期的层中。这是一种隐含的深度监督,因为早期的层可以从最终的分类层直接获得监督。
3.2 Parameter & Computational Efficiency
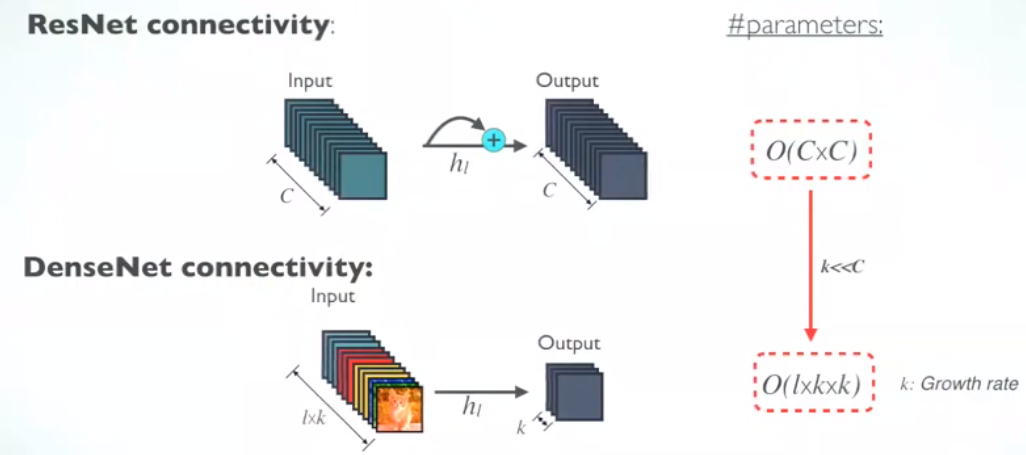
对于每个层,RetNet 中的参数与c×c成正比,而 DenseNet 中的参数与1×k×k成正比。
由于 k << C, 所以 DenseNet 比 ResNet 的size更小。
3.3 More Diversified Features

由于 DenseNet 中的每一层都接收前面的所有层作为输入,因此特征更加多样化,并且倾向于有更丰富的模式。
3.4 Maintains Low Complexity Features
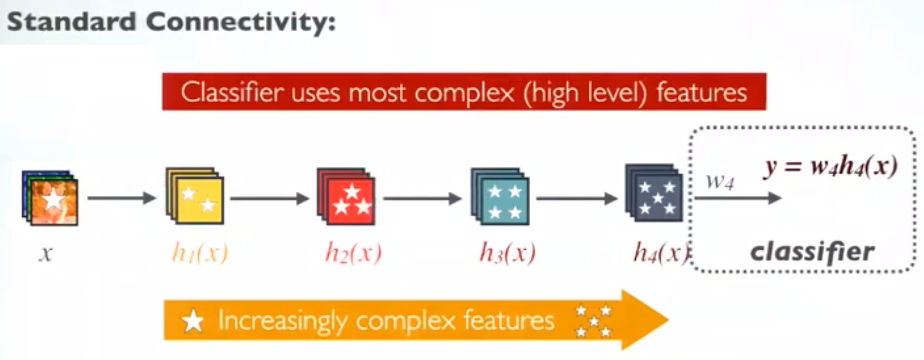
在标准ConvNet中,分类器使用最复杂的特征。
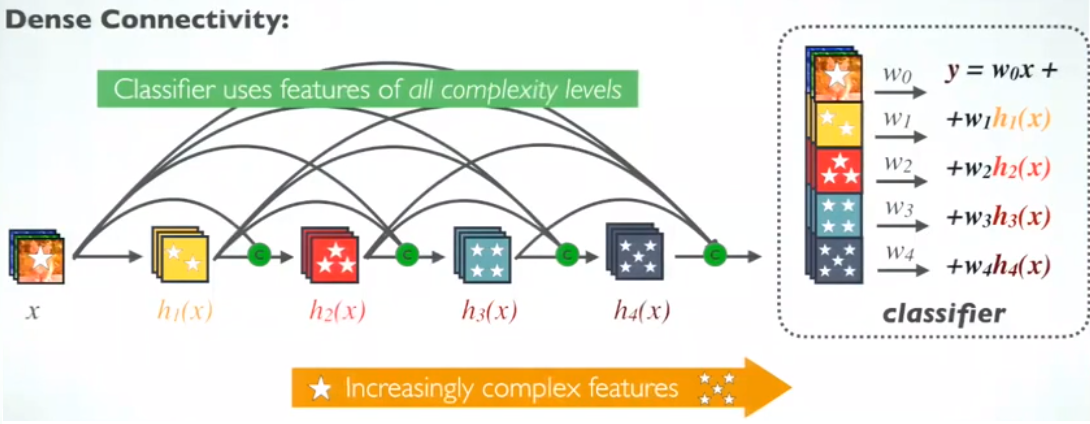
在 DenseNet 中,分类器使用所有复杂级别的特征。它倾向于给出更平滑的决策边界。它还解释了为什么 DenseNet 在训练数据不足时表现良好。
4. CIFAR & SVHN 小规模数据集结果
4.1 CIFAR-10
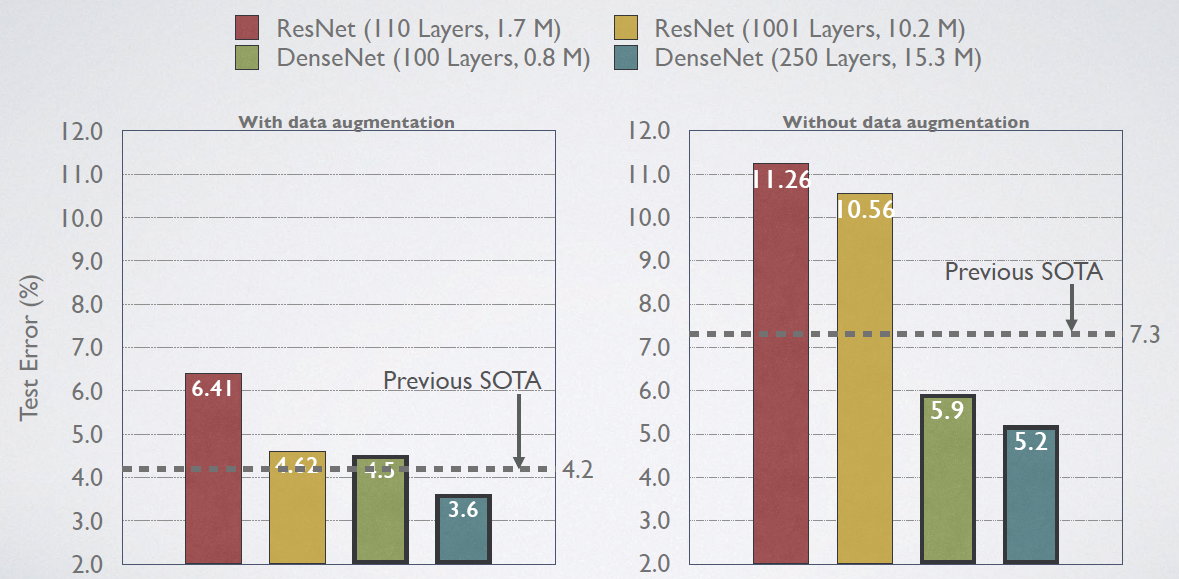
Pre-Activation ResNet is used in detailed comparison.
数据增强(C10+),测试误差:
- Small-size ResNet-110: 6.41%
- Large-size ResNet-1001 (10.2M parameters): 4.62%
- State-of-the-art (SOTA) 4.2%
- Small-size DenseNet-BC (L=100, k=12) (Only 0.8M parameters): 4.5%
- Large-size DenseNet (L=250, k=24): 3.6%
无数据增强(C10),测试误差:
- Small-size ResNet-110: 11.26%
- Large-size ResNet-1001 (10.2M parameters): 10.56%
- State-of-the-art (SOTA) 7.3%
- Small-size DenseNet-BC (L=100, k=12) (Only 0.8M parameters): 5.9%
- Large-size DenseNet (L=250, k=24): 4.2%
在 Pre-Activation ResNet 中出现严重的过拟合,而 DenseNet 在训练数据不足时表现良好,因为DenseNet 使用了复杂的特征。
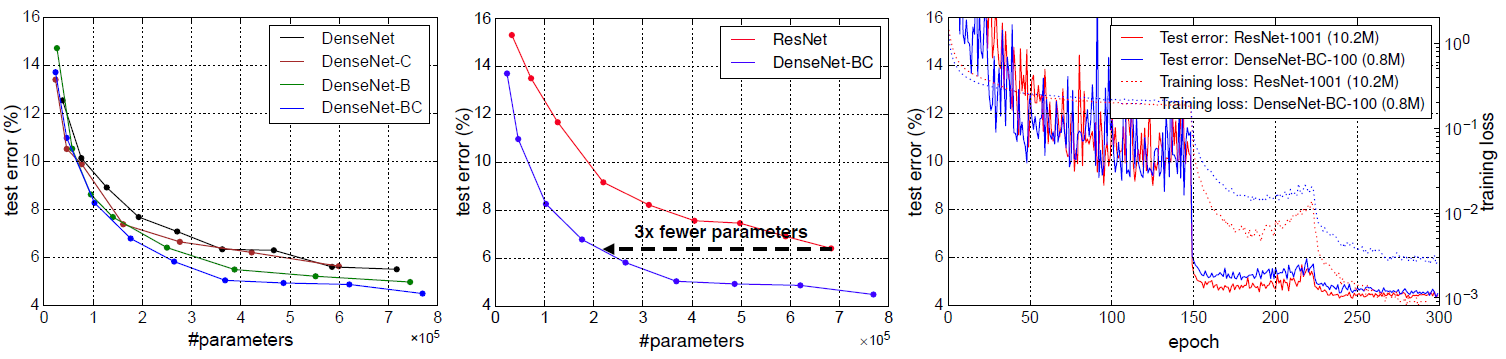
- 左:DenseNet-BC 获得最佳效果。
- 中:Pre-Activation ResNet 已经比 alexnet 和 vggnet 获得更少的参数,DenseNet-BC(k=12)的参数比 Pre-Activation ResNet 少3×10,测试误差相同。
- 右:与 Pre-Activation ResNet-1001有10.2m 参数相比,0.8 参数的 DenseNet-BC-100 具有相似的测试误差。
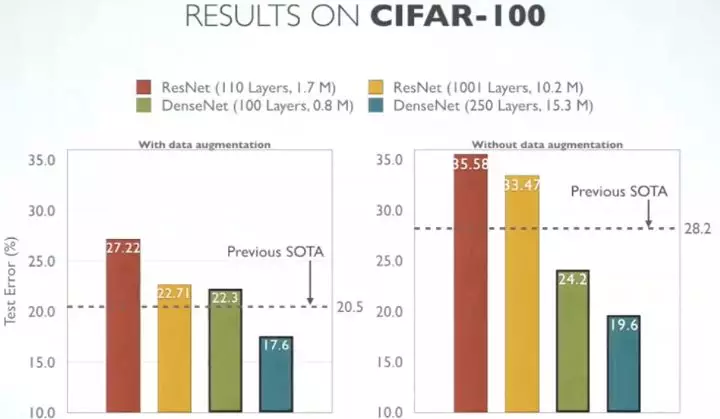
4.2 CIFAR-100
CIFAR-100类似的趋势如下:
4.3 Detailed Results
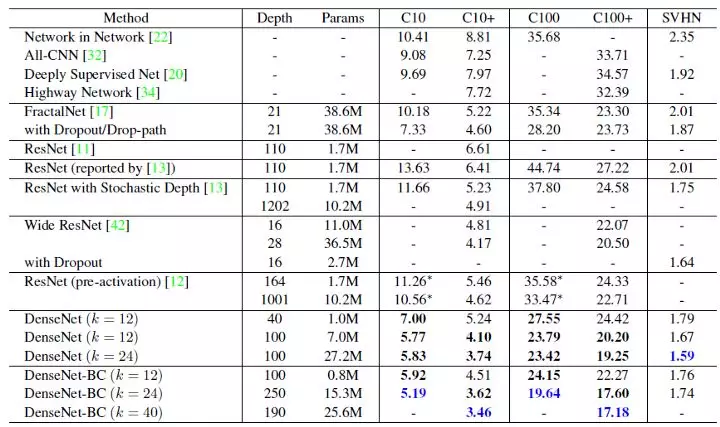
SVHN 是街景房屋编号的数据集。蓝色代表最好的效果。DenseNet-BC 不能得到比基本 DenseNet 更好的结果,作者认为 SVHN 是一项相对容易的任务,非常深的模型可能会过拟合。
5. ImageNet 大规模数据集结果
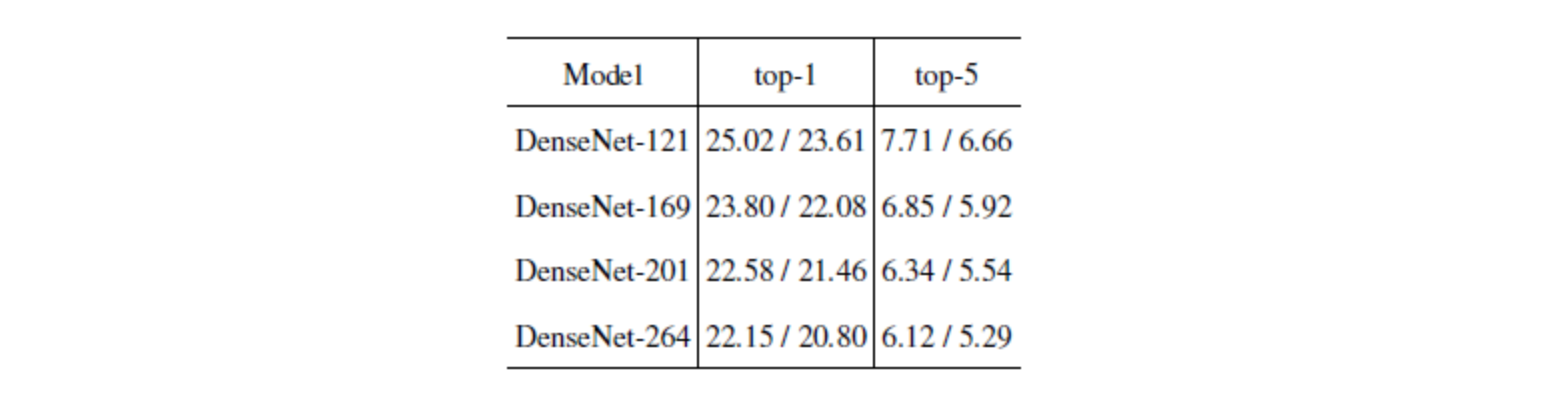
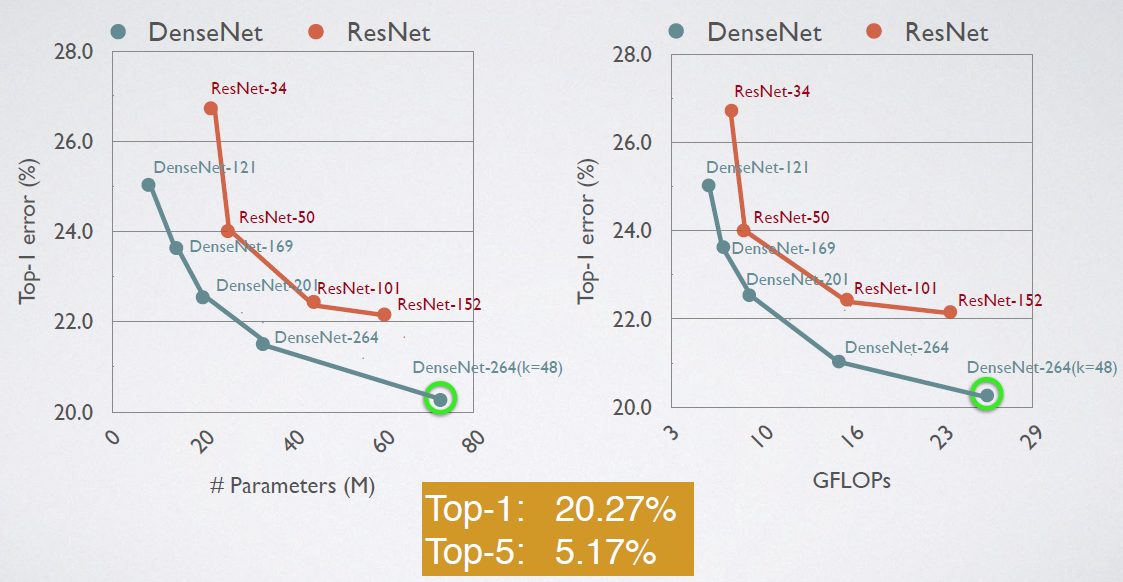
- 左:20M参数的DenseNet-201与大于40M参数的ResNet-101产生类似的验证错误。
- 右:相似的计算次数趋势(GOLOPS)。
- 底部:DenseNet-264(k=48)最高误差为20.27%,前5误差为5.17%。
6. 特征复用的进一步分析
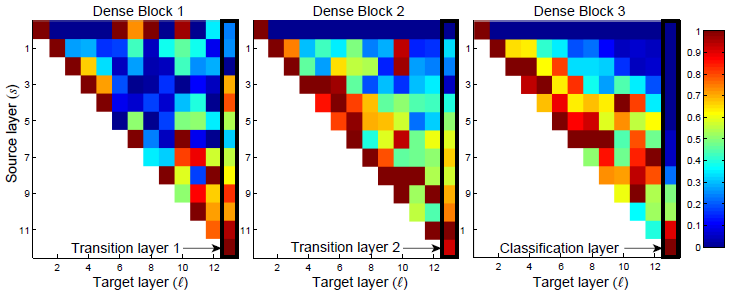
- 从非常早期的层中提取的特征被同一 Dense Block 中的较深层直接使用。
- 转换层的权重也分布在前面的所有层中。
- 第二和第三 dense block 内的各层一贯地将最小权重分配给转换层的输出。(第一行)
- 在最终分类层,权重似乎集中在最终 feature map 上。一些更高级的特性在网络中产生得很晚。
Reference
[2017 CVPR] [DenseNet]
Densely Connected Convolutional Networks
原文链接:
https://towardsdatascience.com/review-densenet-image-classification-b6631a8ef803
- Title: DenseNet — Dense卷积网络(图像分类)
- Author: Zhanhang (Matthew) ZENG
- Link: https://zengzhanhang.com/2019/07/21/densenet/
- Released Date: 2019-07-21
- Last update: 2020-05-16
- Statement: All articles in this blog, unless otherwise stated, are based on the CC BY-NC-SA 4.0 license.

